6.5 KiB
| title | date | tags | categories | |||
|---|---|---|---|---|---|---|
| 博客全文检索施工记录 | 2019-7-9 10:15:00 |
|
|
最近发现了一个提供全文检索服务的Algolia, 可以上传内容索引并且提供访问接口执行全文检索 可惜尝试之后发现上传内容索引时如果内容太长就会失败, 这就导致只能在摘要范围内搜索 因为已经有了后端API的支持, 所以考虑自己实现一下
分词
全文检索的关键步骤是分词, 中文分词做的比较好的就是jieba分词了 还提供了nodejs的包可以直接调用 当然底层仍是C++代码, 安装依赖时需要使用node-gyp编译 我在windows环境始终没能成功(已安装python和windows-build-tools), linux和mac环境倒是十分顺利
基本的调用方式
import * as nodejieba from 'nodejieba'
nodejieba.load({}) // 加载词库, 只需调用一次
nodejieba.cut('这里是需要执行分词的文本', true)
对于文章内容和查询关键字都需要做分词操作
保存分词结果
在mongodb当中使用两个集合分别保存文章正文和分词结果 (因为mongodb限制每个文档的最大体积16MB, 这样做也是为了避免长文章导致的无法保存)
article集合
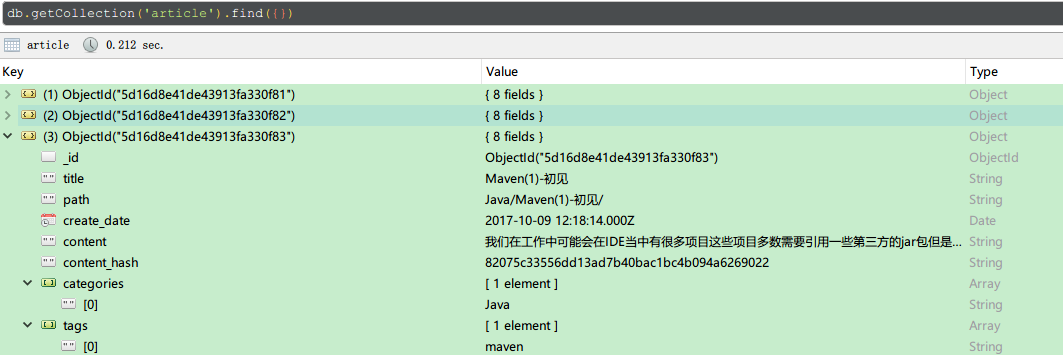
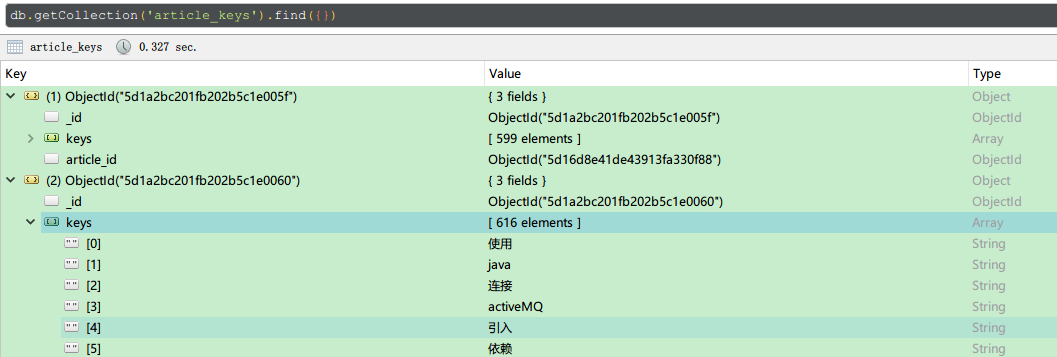
article_keys集合
这个集合用来保存分词的结果
执行检索
需要重点理解一下mongodb的aggregate, 这是一个管道操作, 接受一个数组
数组中的每个元素都是一步操作, 前一步操作的执行结果传递给下一步操作继续处理
检索需要实现以下几个目标
- 自动分词: 比如"函数解决"这类常见中文词汇, 自动拆分为"函数","解决"
- 强制分词: 比如"存储 过程"其中包含空白符分隔的, 强制拆分为"存储","过程"
- 非完全匹配: 比如分词为"函数","解决", "函数"有匹配, "解决"无匹配, 也能查到"函数"匹配的
- 相关度降序: 出现频率高的文章在前, 比如"函数","解决"在A文章共出现5次, B文章共出现3次, 则A文章在前
- 摘要提取: 对于关键词所在正文内容提取, 关键词出现位置靠近则合并提取范围, 关键词过多则省略靠后的摘要
1和2可以利用jieba分词和正则做到, 查询过程主要实现3和4, 5在查询之后对正文处理做到
以下是目前设计的查询方案 主要目的是在一次查询当中做到计数和分页截取
const splitedWords = ['函数', '过程'] //对查询关键词的分词处理结果
const page = { // 分页信息
start: 0,
limit: 10
}
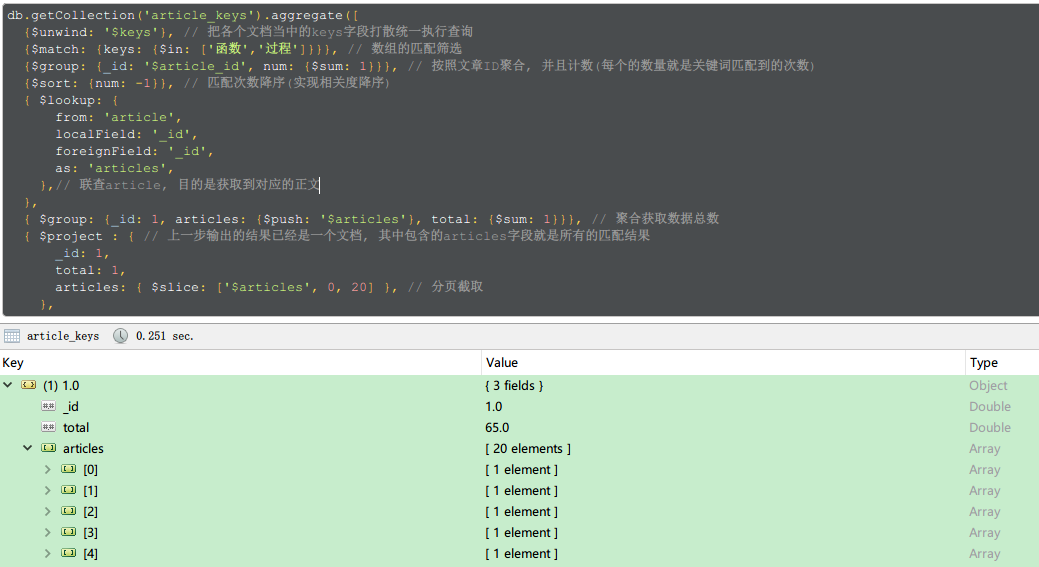
db.getCollection('article_keys').aggregate([
{$unwind: '$keys'}, // 把各个文档当中的keys字段打散统一执行查询
{$match: {keys: {$in: splitedWords}}}, // 数组的匹配筛选
{$group: {_id: '$article_id', num: {$sum: 1}}}, // 按照文章ID聚合, 并且计数(每个的数量就是关键词匹配到的次数)
{$sort: {num: -1}}, // 匹配次数降序(实现相关度降序)
{ $lookup: {
from: 'article',
localField: '_id',
foreignField: '_id',
as: 'articles',
},// 联查article, 目的是获取到对应的正文
},
{ $group: {_id: 1, articles: {$push: '$articles'}, total: {$sum: 1}}}, // 聚合获取数据总数
{ $project : { // 上一步输出的结果已经是一个文档, 其中包含的articles字段就是所有的匹配结果
_id: 1,
total: 1,
articles: { $slice: ['$articles', page.start, page.limit] }, // 分页截取
},
},
])
操作输出的结果就是包含分页数据和数据总数的一个对象了
需要注意的是, 倒数第二步执行聚合之后, 因为已经聚合为一个文档, 所以就不能再用$skip和$limit了
只能使用数组的操作函数$slice, 第一个参数为操作对象, 第二个参数是截取起点, 第三个参数是截取长度
摘要提取
这里是TypeScript语法, 使用原生JavaScript也一样
/**
* 创建文章搜索结果摘要, 使用<strong>标签高亮关键词
* @param content 文章正文内容
* @param keyWords 关键词们
* @param cutLen 每个关键词所在位置的截取区域长度
* @returns 文章摘要信息
*/
private createSummary(content: string, keyWords: string[], cutLen: number): string {
const cutRanges: number[][] = []
keyWords.forEach((keyWord: string) => {
const keyWordIndex: number = content.indexOf(keyWord)
if (keyWordIndex === -1) {
return
}
const start: number = keyWordIndex - cutLen / 2 < 0 ? 0 : keyWordIndex - cutLen / 2
const end: number = keyWordIndex + cutLen / 2 + keyWord.length > content.length ? content.length : keyWordIndex + cutLen / 2 + keyWord.length
cutRanges.push([start, end])
})
cutRanges.sort((item1: number[], item2: number[]) => {
if (item1[0] > item2[0]) {
return 1
} else if (item1[0] < item2[0]) {
return -1
} else {
return 0
}
})
let summary = ''
let lastCutEnd = 0
for (let index = 0 ; index < cutRanges.length ; index++) {
const cutStart: number = cutRanges[index][0]
let cutEnd: number = cutRanges[index][1]
// 如果当前范围的末尾达到或超过下一个范围的开头
while (index < cutRanges.length - 1 && cutRanges[index][1] >= cutRanges[index + 1][0]) {
// 则把范围扩大到下一个范围的末尾
cutEnd = cutRanges[index + 1][1]
// 并将索引向前推进
index ++
}
if (summary.length) {
summary += ' ... '
}
summary += content.substring(cutStart, cutEnd)
lastCutEnd = cutEnd
if (summary.length > 150) { break }
}
summary = cutRanges[0][0] > 0 ? ('... ' + summary) : summary
summary += lastCutEnd < content.length ? ' ...' : ''
keyWords.forEach(keyWord => {
summary = summary.replace(new RegExp(CommonUtils.escapeRegexStr(keyWord), 'g'), `<strong>${keyWord}</strong>`)
})
return summary
}
主要思路就是找到每一个关键词所在位置, 确定截取区域, 注意几点
- 截取区域到达全文开头或者末尾的处理
- 截取范围按照升序排列以便截取后组合的结果正确
- 两个相邻的关键词如果截取范围相连或者有重叠, 需要将两者的范围合并
- 摘要总长度限制
性能表现
分词后的数据总量大约56万
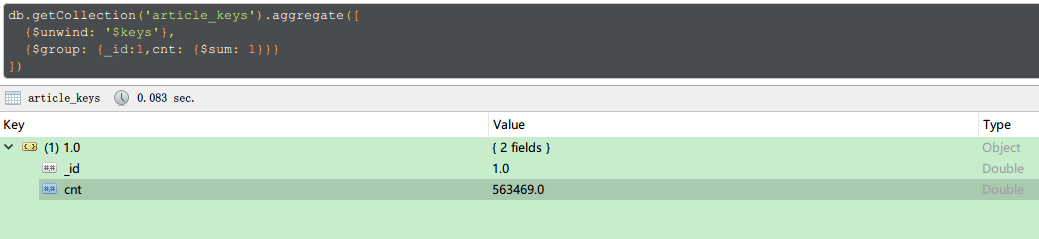
添加索引之后基本每次查询的时间大约200ms, 基本还是不错的