7.4 KiB
| title | date | tags | categories | |||
|---|---|---|---|---|---|---|
| TensorFlow.js初见(1) | 2021-4-1 15:00:28 |
|
|
TensorFlow是Google发布的一个机器学习框架,可以构建和训练机器学习模型
把机器学习的应用门槛降低了很多
并且有对应的js版本,可以在nodejs或者浏览器环境运行
基础知识准备
张量(Tensors)
tf.Tensor是TensorFlow.js中的最重要的数据单元,它是一个形状为一维或多维数组组成的数值的集合。tf.Tensor和多维数组其实非常的相似。
一个tf.Tensor还包含如下属性:
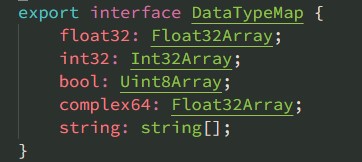
rank: 张量的维度shape: 每个维度的数据大小,代表了张量的形状dtype: 张量中的数据类型
import * as tf from '@tensorflow/tfjs-node'
const a = tf.tensor([[1, 2], [3, 4], [5, 6, 7]])
console.log('rank:', a.rank) // 2
console.log('shape:', a.shape) // [3,2]
console.log('dtype:', a.dtype) // float32
a.print()
/*
[[1, 2],
[3, 4],
[5, 6]]
*/
从上述执行结果可以发现,超出边界的数据会被舍弃 tf.tensor函数包含三个参数,后两个参数是可选的
- values: 原始数据
- shape: 数组,指定每个维度的数据大小(不指定则根据原始数据的多维数组层级决定)
- dtype: 数据类型,只能是下面的几种值

操作
张量可以进行一些处理和运算,但是张量对象本身是不可变的 这些操作都会产生新的张量对象
改变形状
const a = tf.tensor([[1, 2], [3, 4]]);
const b = a.reshape([4, 1]);
b.print();
/*
[[1],
[2],
[3],
[4]]
*/
上述代码表示将张量改变为第一层维度的长度为4,第二层维度的长度为1
运算
// 对所有数据平方
const x = tf.tensor([1, 2, 3, 4])
const y = x.square() // 相当于 tf.square(x)
y.print()
// 将两个张量逐个相加
const a = tf.tensor([1, 2, 3, 4])
const b = tf.tensor([10, 20, 30, 40])
const y = a.add(b) // 相当于 tf.add(a, b)
y.print()
执行add的情况两个张量的形状和数据类型必须一致
模型训练
作为一个初见HelloWorld,这是一个垃圾分类识别图片的demo 使用nodejs环境来执行这个过程
1、安装nodejs版本的TensorFlow
npm install @tensorflow/tfjs-node
当然它底层是在调用C++库,在windows环境需要使用node-gyp进行编译 相比之下,mac和linux环境安装会顺利很多
为了代码的编写方便,我也添加了TypeScript的基础环境
"dependencies": {
"@tensorflow/tfjs-node": "^3.3.0",
"typescript": "^4.2.3"
},
"devDependencies": {
"ts-node": "^9.1.1"
}
2、准备训练素材
下载地址
 这里有4种类型的垃圾,每一种里面都有大量的图片
这里有4种类型的垃圾,每一种里面都有大量的图片
3、读取训练素材
这里主要就是一些nodejs当中读写文件的API
/*
根据实际情况定义 trainDir 和 outputDir
也就是读取训练素材的目录和产出输出的目录
*/
// 读取目录,获取到的是固定顺序的4种类型的名称
const types = fs.readdirSync(trainDir)
// 写入到文件,为后续的模型使用做准备
fs.writeFileSync(`${outputDir}/types.json`, JSON.stringify(types))
const imageData: {imagePath: string, dirIndex: number}[] = []
types.forEach((dir: string, dirIndex: number) => {
// 获取每个类型当中所有的图片名称
const imgNames = fs.readdirSync(`${trainDir}/${dir}`)
imgNames.forEach(imgName => {
imageData.push({
imagePath: `${trainDir}/${dir}/${imgName}`,
dirIndex // 这个index用于区分该图片属于哪种类型
})
})
})
这里拿到的imageData是一个包含所有训练素材路径和类别索引的数组
4、图片数据转化为张量
/**
* 图片数据处理
* @param buffer 图片数据Buffer
* @returns
*/
const img2x = (buffer: Buffer) => {
// tf.tidy 执行后就会清除所有的中间张量,并释放它们的GPU内存(相当于优化运行过程, 这一层包装也可以不要)
return tf.tidy(() => {
// 图片格式转换
const imgTs = tf.node.decodeImage(new Uint8Array(buffer))
// 图片尺寸转换
const imgTsResized = tf.image.resizeBilinear(imgTs, [224, 224])
// 将像素值归一化到[-1, 1]
/**
* 图片像素值是[0, 255]
* 先减去 255 / 2, 此时区间是[-127.5, 127.5]
* 再除以 255 / 2, 此时区间是[-1, 1]
* reshape进行模型转换
* 224,224代表尺寸 3代表RGB图片 1代表把图片放在数字1(拓展一维)
*/
return imgTsResized.toFloat().sub(255 / 2).div(255 / 2).reshape([1, 224, 224, 3])
})
}
5、对大量训练素材进行处理
由于直接把所有图片读取后转化为张量,会占用大量内存 TensorFlow支持使用生成器函数进行分批处理
imageData为第3步中得到的图片路径数据
// 将图片数据打乱顺序 便于观察训练效果
tf.util.shuffle(imageData)
// 防止数据过多全部读入内存无法容纳
// 所以使用生成器函数进行分批读取
const dataset = tf.data.generator(function* () {
const batchSize = 32
for(let index = 0 ; index < imageData.length ; index += batchSize) {
const end = Math.min(index + batchSize, imageData.length)
yield tf.tidy(() => {
const inputs = []
const labels: number[] = []
for(let readIndex = index ; readIndex < end ; readIndex ++) {
// 同步读取图片,得到Buffer对象
const imgBuffer = fs.readFileSync(imageData[readIndex].imagePath)
inputs.push(img2x(imgBuffer))
labels.push(imageData[readIndex].dirIndex)
}
// 封装为Tensor的嵌套数组
const xs = tf.concat(inputs)
const ys = tf.tensor(labels)
return {xs, ys}
})
}
})
6、加载模型进行复用
这里使用MobileNet这个模型进行复用 所需文件: model.json group1-shard1of1.bin
// 加载模型
const mobilenet = await tf.loadLayersModel(`file://${process.cwd()}/resource/model.json`)
// 复用该模型 并截断部分
const model = tf.sequential() // 定义一个连续的模型
for(let i = 0 ; i <= 86 ; i++) {
const layer = mobilenet.layers[i]
layer.trainable = false
model.add(layer)
}
model.add(tf.layers.flatten()) // 数据扁平化
model.add(tf.layers.dense({ // 隐藏层
units: 10, // 神经元个数
activation: 'relu', // 激活函数
}))
model.add(tf.layers.dense({ // 输出层
units: types.length,
activation: 'softmax'
}))
// 训练模型
// 定义损失函数和优化器
model.compile({
loss: 'sparseCategoricalCrossentropy', // 损失函数
optimizer: tf.train.adam(), // 优化器
metrics: ['acc'/* 准确度的度量 */] // 度量单位
})
7、执行训练
如果是一次性读取所有文件,直接使用fit方法
如果是生成器函数分批读取的,使用fitDataset方法
// 使用fit方法进行训练(让模型参数尽可能拟合图片数据)
await model.fitDataset(dataset, {
epochs: 20 // 执行多少轮训练
})
// 使用save方法保存模型文件
await model.save(`file://${process.cwd()}/output`)
执行完毕后,就在output里面得到了训练好的模型文件